
고정 헤더 영역
상세 컨텐츠
본문
안녕하세요 이스트소프트입니다.
오늘은 여러분들께 캐글(Kaggle) 소식을 전달해드리려고 합니다.
이스트소프트 기업부설연구소 A.I. PLUS Lab의 한 개발자가 캐글(Kaggle)챌린지에 입상했다는 소식인데요~
캐글은 아마도 데이터 사이언스나 머신러닝에 관심이 있는 분은 이미 알고 계실 것 같은데요~ 캐글은 2010년 설립된 빅데이터 솔루션 대회 플랫폼 회사입니다. 21세기에서 가장 섹시한 직업으로 뽑힐 만큼 데이터 사이언티스트는 요즘 가장 큰 화두로 떠오르면서 캐글 규모도 같이 성장하게 되었는데요~ 결국 2017년 3월 구글은 캐글을 인수하게 되었습니다.
인공지능 선도 기업으로 발을 뻗어가고 있는 이스트소프트에서도 캐글 챌린지에 도전하고 계신 개발자들이 참 많이 있는데요~ 이번에 캐글(Kaggle) 챌린지에 입상하신 개발자가 있어 인터뷰를 요청드렸습니다! 흔쾌히 요청에 응해주는 모습이 참 넉넉해 보였습니다! 그럼 어떻게 캐글 챌린지에 입상하게 되었고 성공 비결은 무엇이었는지 이스트소프트 A.I. PLUS Lab 박진모 차석을 만나보도록 하겠습니다!
Interview

자기 소개 부탁드립니다.
안녕하세요. 저는 A.I. PLUS Lab에서 Research Engineer로 근무하고 있는 박진모입니다.
과거에는 게임업계에서 Software Engineer로 약 10년 정도 일했는데요,
딥러닝에 매력을 느끼고, 2016년 가을 즈음에 A.I.PLUS Lab에 합류하여 즐겁게 연구, 개발 중입니다.
A.I. PLUS Lab 소개를 간략히 부탁드립니다.
A.I. PLUS Lab은 현실의 문제에 결합했을 때 탁월한 효과를 낼 수 있는 인공지능 기반 기술을 연구, 개발하고 있습니다. 인공지능으로 사람 같은 로봇을 만드는 것은 아직 시간이 더 필요하겠지만, 우리는 일상에 편의를 제공하고 다양한 비즈니스에 발생하는 비효율을 개선하는 데 인공지능 기술을 결합해 이미 탁월한 효과를 입증하고 있습니다.
온라인 쇼핑몰에서 패션을 제안하고 안경을 가상 착용해볼 수 있는 기술, 기존의 분석 기술로는 탐지하기 어려운 변종 악성코드를 탐지해내는 딥러닝 기술, 시각 지능과 언어 지능을 활용한 범죄 수사 기술, 텍스트 데이터를 분석해 필요한 자재를 자동으로 예측하는 기술, 판매 가격을 최적화해 이윤을 최대화하는 기술, 금융시장에서 변수 간 복잡한 관계를 분석하고 시장의 변화를 보다 빨리 감지해 투자 기회를 포착하는 기술 등 다양한 영역에서 활용되는 기반 기술을 연구, 개발하고 있습니다. 이미 여러 제품을 출시해 시장에 공급하고 있고, R&D 챌린지 우승이나 해외 컨퍼런스 발표 등을 통해 꾸준히 성과를 입증하고 있습니다.
가장 인상 깊은 A.I. PLUS Lab의 개발 or 조직 문화를 뽑는다면?
연구소의 큰 방향성에서만 벗어나지 않는다면, 자유롭게 연구 주제를 선택하여 연구할 수 있습니다. 관심 있는 주제가 같은 멤버들끼리는 모여서 함께 스터디하고, 토론합니다. 이러한 과정들은 각 멤버들이 주도적으로 이루어집니다.
일반적인 개발 업무와 달리 연구는 올바른 방법이 정해져있지 않습니다. 다양한 가능성을 열어두고, 여러 번의 시도와 실패 끝에서야 원하는 목표를 달성할 수 있습니다. 연구소가 하나하나 성과를 이루어 나가는 데에는 멤버들이 스스로 자유롭게 연구에 몰입할 수 있도록 하는 문화가 크게 기여한 것 같습니다.

캐글에 참하게 된 계기는?
실질적인 문제 해결을 통한 딥러닝 모델 개발 역량 향상을 위해 모든 비전 관련 챌린지에 참가해보려 노력하고 있습니다. 문제 자체는 실제 담당 업무와 다소 차이가 있더라도 각 문제에 내포되어 있는 어려움들은 업무에서 마주치는 어려움들과 유사한 경우가 많습니다. 연구를 위한 문제들과 달리 실제 문제에서는 데이터의 불균형, 레이블 노이즈 또는 데이터의 양 등으로 인한 어려움이 많은데, 캐글 챌린지를 통해 이러한 어려움들을 극복하면서 많은 것을 배울 수 있었습니다.
Humpback Whale Identification 챌린지의 경우에는 현재 연구소에서 참여하고 있는 유사 안경 검색 문제와 유사한 부분이 매우 많아서 업무에도 직접적인 도움을 줄 수 있을 것으로 생각했습니다.
차석님께서 수상하신 챌린지를 간단하게 소개해주세요~
Human Protein Atlas Image Classification
Human Protein Atlas(이하 HPA) Image Classification 챌린지는 현미경 사진의 단백질 복합 패턴을 분류하는 문제입니다. 세포의 단백질을 시각화한 이미지는 생물 의학 연구에서 널리 사용되며, 이 세포는 의학의 새로운 돌파구를 위한 열쇠입니다. 그러나 이러한 이미지는 수동으로 평가할 수 있는 것보다 훨씬 빠른 속도로 생성됩니다. 따라서 인간의 세포와 질병에 대한 이해를 가속화하기 위해서는 생물 의학 이미지 분석 자동화의 필요성이 그 어느 때보다 커졌습니다.
HPA Image Classification 챌린지에서는 약 31,100 장의 세포 이미지를 학습시켜 28 종의 단백질 패턴을 분류해야 합니다. 각 이미지에는 여러 개의 단백질 패턴이 포함될 수 있으며 평가 지표로는 macro F1 score가 사용됩니다.
Humpback Whale Identification 챌린지는 고래 꼬리 사진으로부터 고래의 개체(Identity)를 알아내는 문제입니다. 수 세기에 걸친 포경 이후 감소된 고래 개체 수를 회복하는 일은 대양 온난화와 어업계 등의 영향으로 어려움을 겪고 있습니다. 고래 보전을 위해 과학자들은 사진 감시 시스템을 통해 고래의 해양활동을 감시합니다. 과학자들은 고래의 꼬리 모양과 독특한 표식을 사용하여 고래의 개체를 분류, 추적하고 기록합니다. 지난 40년간 대부분의 작업이 개개인의 과학자에 의해 수작업으로 진행되었기 때문에 엄청난 약의 데이터가 사용되지 않고 활용도가 떨어졌습니다.
Humpback Whale Identification 챌린지에서는 약 25,400 장의 고래 꼬리 사진에서 5,004 종의 고래 개체를 분류해야 합니다. 평가 지표로는 Global Average Precision @ 5가 사용됩니다.
한 개가 아니라 두 개 컴피티션에서 입상을 하신거군요... 놀랍습니다.. 어떻게 과제를 해결하셨나요? 과제 해결 스토리가 궁금합니다
[Humpback Whale Identification 해결 과정]
문제와 데이터 셋을 꼼꼼히 살펴본 결과, 이 문제는 Face Identification 문제와 매우 유사하다는 것을 알게 되었습니다. 연구소의 동료들이 이 문제에 대한 경험이 있었기 때문에 기본 모델의 구조를 결정하는데 어려움이 없었습니다. 시작은 Face Identification에서 가장 좋은 성능을 보이는 ArcFace 모델을 기본으로 시작하였습니다.

Face Identification을 위한 파이프라인 따라 먼저 Bounding Box Detector, Landmark Detector 모델을 학습시키고, 그 결과를 이용하여 ArcFace 모델을 학습시켰습니다. 테스트 이미지에 대한 결과 생성을 위해 Open-set Face Identification에서 사용되는 일반적인 방법을 적용하였습니다. 몇 가지 Hyper-parameter 튜닝 후에 5위 이내의 순위를 기록할 수 있었습니다.
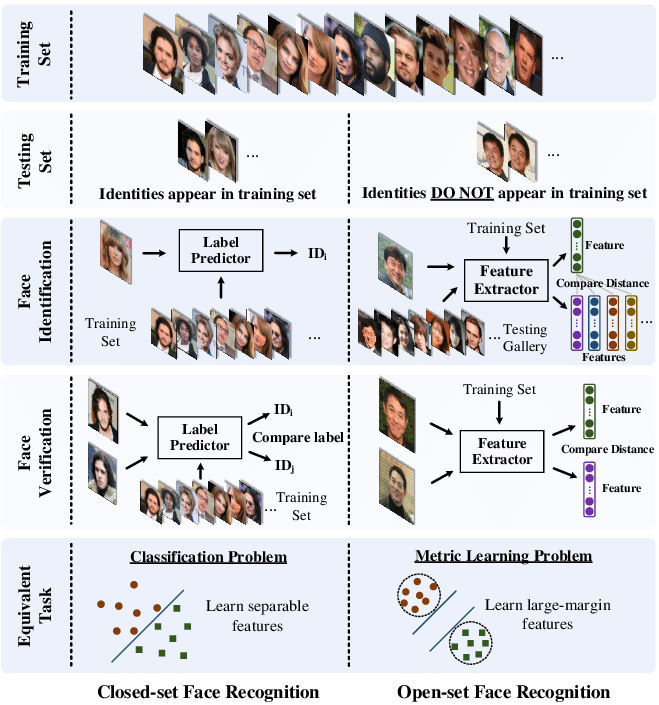
이후, Data Augmentation 기법 변경, Bounding Box Detector, Landmark Detector 모델 개선 등을 통해 조금씩 스코어를 올려 꾸준히 순위를 유지하였습니다.
동시에 데이터 셋과 모델의 결과를 분석하며 두 가지 중요한 공략 지점을 발견하였습니다. 첫째는 사진을 좌우 반전하면 새로운 고래 개체의 데이터 셋을 얻을 수 있다는 것입니다. 둘째는 학습 데이터 셋의 상당히 많은 이미지가 잘못 레이블링 되어있다는 것이었습니다.

이를 활용하기 위해, 먼저 모든 이미지를 좌우 반전하여 고래 개체의 종류를 2배로 늘렸습니다. 그리고, 학습된 모델의 결과를 기반으로 잘못된 이미지를 새로 레이블링하였습니다. 이렇게 개선된 데이터 셋을 이용하여 새로 학습한 결과 큰 스코어의 향상을 얻을 수 있었습니다.
이후, Inference 방법 변경, ensemble 등을 통해 꾸준히 1~3위를 유지하다 최종 순위 3위로 마무리하였습니다.

자세하고 친절한 답변 감사드립니다 차석님. 그럼 앞으로 Kaggle 관련된 향후 계획이나 목표가 있으신가요?
우선 kaggle의 가장 높은 등급인 grand-master가 되는 것이 목표입니다. 그동안은 혼자 챌린지에 참가했었는데요, Kaggle에 관심을 가지고 있는 분들이 사내에도 꽤 많이 있다는 것을 알게 되었습니다. 동료분들과 함께 고민하며 문제를 해결해나간다면 더 많은 것을 배우고, 더 좋은 성적을 거둘 수 있지 않을까 생각됩니다.
Humpback Whale Identification의 솔루션은 HappyWhale.com에 적용되어 매우 만족스럽게 사용되고 있다는 내용을 챌린지 호스팅 팀으로부터 전달 받았습니다. 딥러닝 기술을 이용하여 사회적으로 기여할 수 있었다는 사실에 매우 보람을 느꼈으며, 앞으로도 의료/환경 분야의 챌린지에 적극적으로 참여하여 더 나은 세상을 만드는데 조금이나마 기여하고 싶습니다.
* 이미지 출처
- 논문명: ArcFace: Additive Angular Margin Loss for Deep Face Recognition
- 논문 링크: https://arxiv.org/pdf/1801.07698.pdf
- 논문명: SphereFace: Deep Hypersphere Embedding for Face Recognition
- 논문 링크: https://arxiv.org/pdf/1704.08063.pdf
'PEOPLE' 카테고리의 다른 글
| 이스트소프트, 세계적인 AI컨퍼런스 CVPR서 기술 발표 (4) | 2019.10.25 |
|---|---|
| '슈퍼맨이떳다' 남자의 육아휴직이 당연한 기업문화 (0) | 2019.08.05 |
| Kotlin Night - 코틀린 나이트를 접수하다 (4) | 2019.04.10 |
| 주중에는 개발자, 주말에는 프로 풋살선수 "끈기만 있으면 됩니다" (10) | 2018.12.10 |
댓글 영역